
图片源于网络 侵删
Python基础
正确使用缩进
缩进,即制表符(键盘上Tab键)用来决定代码之间的逻辑关系,所以在使用选择结构和循环结构,或者是编写函数的时候,务必注意缩进的使用,若使用不恰当,会造成程序报错,如:
1 | while True: |
执行后,在PyCharm中则会显示:
print(“Hello world”)
^
IndentationError: expected an indented block
(想要了解更多常见错误,请戳:Python常见报错)
正确的写法为:
1 | while True: |
执行后,在PyCharm中则会显示:
Hello world
Hello world
Hello world
Hello world
Hello world
…..
正确使用符号
众所周知,编程中实用的符号都为英文符号,初入的萌新大多都会出现:SyntaxError: invalid character in identifier
这正是因为符号使用错误,由下表可见,中英文符号的差距存在差别,编程时值得注意。
| 英文符号 | 中文符号 |
| ; | ; |
| : | : |
| "" | “” |
注释的用法
注释单行内容:
使用 # 注释
注释多行内容:
使用 ‘ ‘ ‘或者“ “ “ 注释
1 | while True: #开始循环 |
标识符及命名规则
标识符
Python中对标识符构成的要求:以数字或者下划线(_)开头,后跟字母、数字、下划线。| 合法名称示例 | 非法名称示例 |
| x | 2x |
| num_1 | a-b |
| python666 | Py 666 |
不要使用单、双下划线开头,Python中会有冲突(尽量避免使用)
不要使用关键字作为标识符,如 False,True
变量与赋值
变量
Python不需要申明数据类型,它能自动识别赋值的类型可用函数type(变量名)判断数据类型。
1 | m=2 |
执行该代码就会输出以下内容,说明赋给m的值2是整型(int)
1 | <class 'int'> |
| 值 | 类型 |
| 2 | int-整型 |
| 2.6 | float-浮点型 |
| 园长 | str-字符串 |
| 2=3j | complex-复数 |
| True | bool-布尔值 |
| [1,2,3,4] | list-列表 |
赋值
- 变量=表达式
1 | x = 100 |
- 链式赋值
1 | x = y = z = 100 |
- 解包赋值
1 | a , b = 100, 50 |
数据的输入与输出
- 输入 input()
- 输出 print()
数值
数值操作
- 内置操作符
| 描述 | 操作符 |
| 加减乘除 | +-*/ |
| 整除 | // |
| 取余 | % |
| 乘方 | ** |
- 内置运算函数
| 描述 | 函数 |
| x的绝对值 | abs(x) |
| 输出(x//y,x%y) | divmod(x) |
| 输出(x**y)%z,z可选 | pow(x,y,[z]) |
| 对x四舍五入,保留ndigits位小数 | round(x,[ndigits]) |
| 返回x1,x2,···xn中的最大值 | max(x1,x2,···xn) |
| 返回x1,x2,···xn中的最小值 | min(x1,x2,···xn) |
math库
使用时需要调用math库
1 | import math |
math库中的数学常数
| 数学形式 | 常数 |
| π | pi |
| e | e |
| ∞ | inf |
| -∞ | -inf |
| 非浮点数标记 | nan |
math库中数值函数
| 数学形式/描述 | 函数 |
| |x| | fabs(x) |
| x%y | fmod(x,y) |
| 浮点数精确求和 | fsum([x,y,....]) |
| 返回x,y的最大公约数(x,y为整数) | gcd(x,y) |
| 返回x整数部分 | trunc(x) |
| 返回x小数和整数部分 | modf(x) |
| 向上取整返回不小于x的最小整数 | ceil(x) |
| 向下取整返回不大于x的最大整数 | floor(x) |
| x! | factorial(x) |
示例:
1 | import math |
x的绝对值为 520.1314
x除以y取余为 -0.0
xyz的和为 1314.52
a,b的最大0.公约数为 5
x的整数部分为 -520
x的小数部分和整数部分分别为 (-0.13139999999998508, -520.0)
不小于兄的最小整数为 -520
不大于x的最大整数位 -521
b的阶乘为 120
math库中的幂对数函数、三角函数
| 数学形式/描述 | 函数 |
| x^y | pow(x,y) |
| e^x | exp(x) |
| √x | sqrt(x) |
| logʙᴀsᴇX | log(X,[BASE]) |
| log₂x | log2(x) |
| lgx | log10(x) |
| 弧度化角度 | degrees(x) |
| 角度化弧度 | radians(x) |
| √(x²+y²)即(x,y)点到(0,0)点的距离 | hypot(x,y) |
| sin x(cos,tan同) | sin(x ) |
| arcsin x(arccos,arctan同) | asin(x ) |
最后编辑与
2020/3/2 22:11:59

字符串的索引与切片
字符串的索引值如下:1 | 正向索引值 0 1 2 3 4 5 |
以下为字符串索引的例子 ① 访问指定字符
1 | s = "python" |
② 访问区间([头下标:尾下标])p
p
1 | s = "python" |
字符串处理与操作
字符串基本运算符
| 运算符 | 描述 |
| + | "yz"+"666"结果为"yz666" |
| * | "yz"*6结果为yzyzyzyzyzyz |
| in | 判断是否为子字符串,"yz"in"yz6"结果为True |
字符串处理函数
| 函数 | 描述 |
| len(x) | 返回字符串长度 |
| str(x) | 将任意类型转换为字符串 |
| chr(x) | 返回Unicode编码为x的字符 |
| ord(x) | 返回x的Uincode编码值 |
| hex(x) | 将整数x转化为16进制,返回小写字符串 |
| oct(x) | 将整数x转化为8进制,返回小写字符串 |
1 | 注: ①大小写字母的Unicode编码都是按顺序排列的 |
内置字符串处理方法
字符串的查找
- find()和rfind()用于查找一个字符串在指定范围(默认为整个字符串)中首次和最后一次的位置,不存在会返回-1
1
2
3
4s = "Thisisyz'sblog,bolgiscool"
print(s.find("blog")) #"bolg"在字符串s中第一次出现的位置
print(s.rfind("is")) #"is"在字符串是中最后一次出现的位置
print(s.find("666"))
10
19
-1
index()和rindex()用于查找一个字符串在指定范围(默认为整个字符串)中首次和最后一次的位置,不存在会抛出异常
用法:字符串.index('要查找的字符')1
2
3
4s = "Thisisyz'sblog,bolgiscool"
print(s.index("blog")) #"bolg"在字符串s中第一次出现的位置
print(s.rindex("is")) #"is"在字符串是中最后一次出现的位置
print(s.index("666"))print(s.index("666"))
ValueError: substring not found
10
19count()用来返回字符串在范围内出现的次数,不存在会返回0
用法:字符串.count('要计数的字符')1
2
3
4s = "python I love python pppp"
print(s.count("p"))
print(s.count("python"))
print(s.count("66"))6
2
0
字符串的分割
split()和 rsplit()方法分别用来以指定字符为分隔符,从原字符串左端和右端开始将其分隔成多个字符串
用法:变量.resplit('分割符',maxsplit=最大分割次数)maxsplit可缺省
1 | a="一,二,三,四,五,六" |
[‘一’, ‘二’, ‘三,四,五,六’]
[‘一,二,三,四’, ‘五’, ‘六’]
[‘H’, ‘E’, ‘L’, ‘L’, ‘O’]
[‘H E’, ‘L’, ‘L’, ‘O’]
可见分割后返回的结果是列表
默认按照空白字符(空格,制表符,换行符)来分割
- partition()和 rpartition()方法分别用来以指定字符串为分隔符将原字符串分隔为 3 个 部分:
分隔符之前的字符串-----分隔符字符串-----分隔符之后的字符串
如果指定的字符串不在原字符串中,则返回原字符串和两个空字符串。
如果字符串中有多个分隔符,则:
partition()方法按从左向右遇到的第一个分隔符来进行分隔;
rpartition()方法按从右向左遇到 的第一个分隔符来进行分隔。
用法:字符串.aprtition('分隔字符')
1 | a="一,二,三,四,三,二,一" |
(‘一,二,’, ‘三’, ‘,四,三,二,一’)
(‘一,二,三,四,’, ‘三’, ‘,二,一’)
字符串的连接
- join()
用法:'连接符.join(字符串)'
1 | s=["2020","04","14"] |
2020-04-14
字符串转换大小写
s = 'This is my blog.'
| 代码 | 效果 |
|---|---|
| s.lower() | 小写 |
| s.upper() | 大写 |
| s.capitalize() | 首字母大写 |
| s.title() | 所有首字母大写 |
| s.swapcase() | 互换大小写 |
示例:
1 | print(s.swapcase()) |
tHIS IS MY BLOG.
字符串替换
- replace()
用法:字符串.replace("被替换内容","替换内容")
1 | s = 'This is my blog.' |
This is 我的 blog.
字符串删除
用法:字符串.strip('删除类容')
- strip() 删除字符串两端字符
- rstrip()删除字符串右端字符
- lstrip()删除字符串左端字符
1 | s = '+++++++WORLD+++++++' |
WORLD
+++++++WORLD
WORLD+++++++
字符串判断
是否以指定字符开始或结束
用法:字符串.endwith('XXX') 返回 True 或 False
| startswith() | 开始 |
| endswith() | 结束 |
1 | s = '2019010088' |
True
字符串类型判断
| isupper() | 是否全为大写 |
| islower() | 是否全为小写 |
| isdigit() | 是否全为数字 |
| isalnum() | 是否为数字或字母 |
| isalpha() | 是否全为字母 |
字符串排版
1 | s = "Hello World" |
=========Hello World==========
Hello World*****
*****Hello World
000000000Hello World
format()格式化法
- -
1 | print("我是{},我的网站地址是{}".format('园长','https://yzyyz.top')) #默认顺序 |
我是园长,我的网站地址是https://yzyyz.top
- -
使用 format()方法格式化字符串的时候,首先需要在“{}”中输入“:”,在“:”之后分别设置<填充字符> <对齐方式> <宽度>
| 项 | 可选值 |
|---|---|
| <填充字符> | “*”,“=”,“ -”等,但只能是一个字符,默认为空格 |
| <对齐方式> | ^(居中)、 <(左对齐)、 >(右对齐) |
| <宽度> | 一个整数,指格式化后整个字符串的字符个数 |
- -
1
2
3print("{:.2f}".format(3.1415926)) # 结果保留 2 位小数
print("{:=^30.4f}".format(3.1415926)) # 宽度 30,居中对齐,“=”填充,保留 4 位小数
print('{:5d}'.format(24)) # 宽度 5,右对齐,空格填充,整数形式输出可知默认填充符是空格,默认对齐方式是右对齐
3.14
============3.1416============
24
混合运算和类型转换
这里记录下*混合运算和类型转换 *
类型自动转换
1 | f = 24 + 24.0 # 输出 48.0 |
混合运算和类型转换
1 | int(2.32) # 转换为整数类型,输出 2 |
2020/4/1 0:30:40

random库概述
这里放几个random库常用函数:
- random()
- randrange()
- randint()
- choice()
- uniform()
- sample()
- shuffle()
- seed()
首先导入random
1 | # random常用函数 |
random()
1 | print(random()) # 返回[0.0,1.0)中一个随机浮点数 |
0.647239093910809
randrange()
1 | print(randrange(2)) #在0,1中选 |
1
0
0
randint()
1 | print(randint(0,2)) #从0,1,2中随机选整数 相当于randrange(0,3) |
2
choice()
1 | s=["随","机","取"] |
随
b
uniform()
1 | print(uniform(1,2)) # 1,2 范围随机小数 |
1.8666232147036852
sample
1 | b='ilovenwafu' |
[‘a’, ‘f’, ‘l’]
shuffle()
1 | d=[1,2,3,4,5,6] #随机d中的元素 |
[3, 4, 1, 2, 5, 6]
seed()
1 | print('盲猜两次随机是一样的结果') |
两次随机是一样的结果
0.9560342718892494
0.9560342718892494

python中列表以及元组的内容较多,写成文章可能会有杂乱感,故我做了张思维导图。
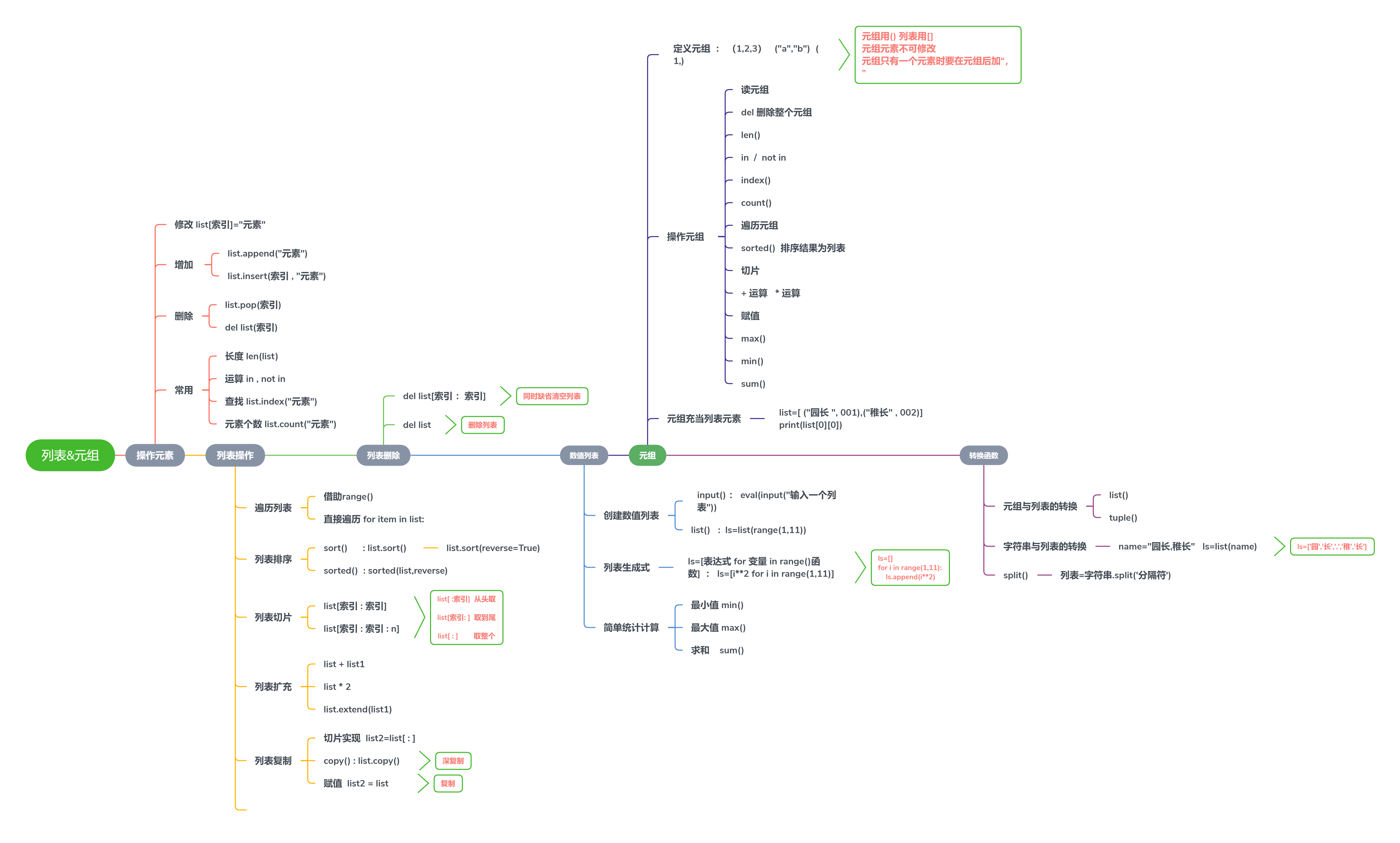
2020/6/14 23:30:19